
When I joined a fintech company as the engineer responsible for the Banking domain, I found a Java monolith with around forty engineers working on it, from six different teams, each pulling in their own direction. Backend and frontend in one codebase. Two completely different business models sharing the same database. Old data layer frameworks, no meaningful observability, almost no security practices, and entity classes shared so freely across the codebase that changing one thing required understanding everything.
My first instinct was to reach for a technical answer. That was the wrong place to start.
Two Business Models, One Codebase
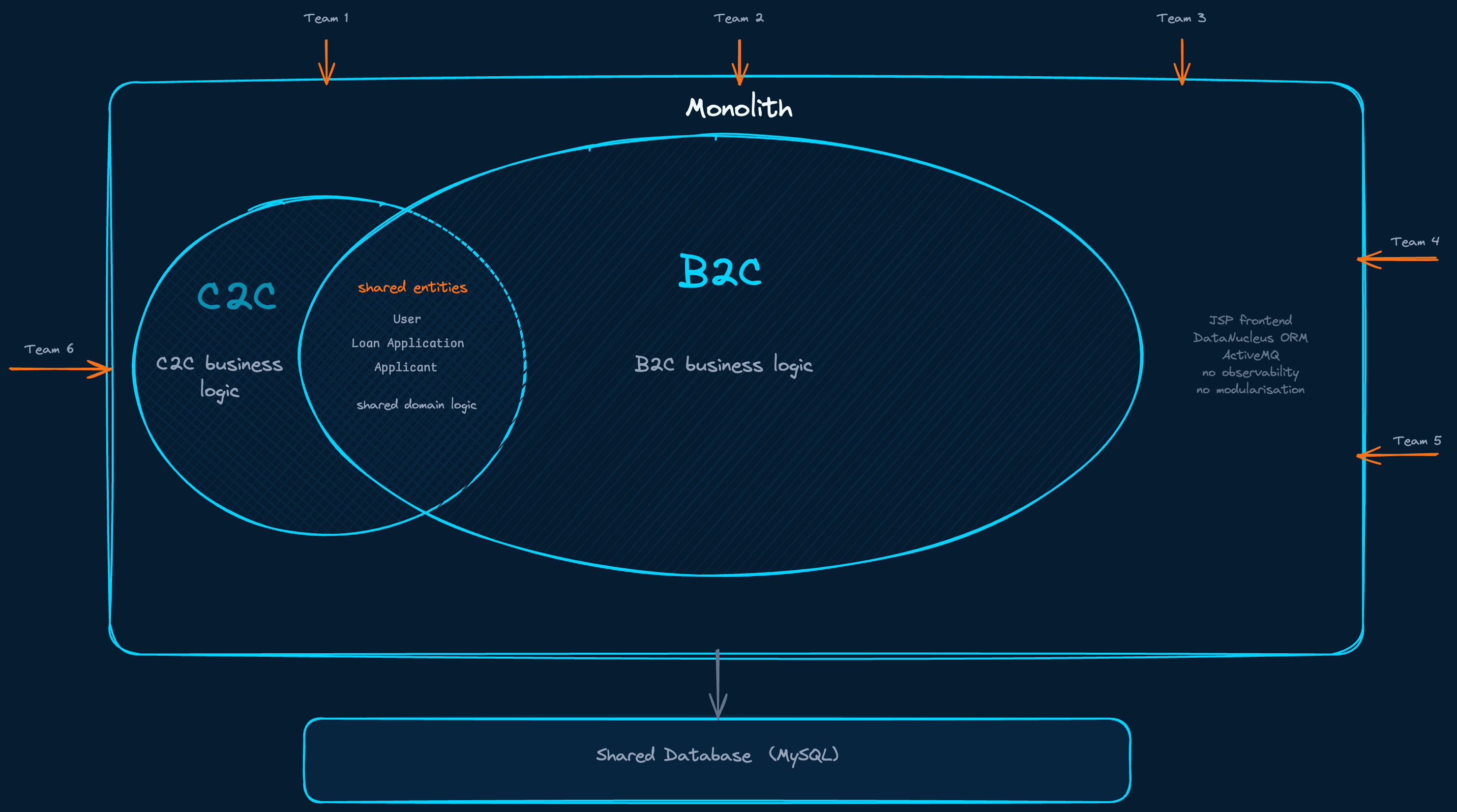
Two business models, one codebase, one database. Forty engineers pulling in six directions.
The company started as a C2C loan platform, customers lending to each other. By the time I arrived, the business had shifted to B2C, a loan comparison platform connecting private customers with bank products. The new model was already proven and growing. But the platform underneath it still carried the full weight of the old one. Customer data, loan application logic, partner integrations, scoring, document management, everything lived inside a single deployable unit originally designed for a business model the company was moving away from.
The C2C part could not simply be switched off. There were legal obligations, existing customers, active contracts. So both models had to coexist, in the same application, on the same database, with entities shared freely between them.
The question was not “how do we build microservices.” The question was how do we untangle two business models that have grown into each other over years, while the business running on top of them cannot stop.
The First Move Was Not Microservices
This is the part I want to be honest about, because most migration stories skip it.
We did not start with microservices. The first thing we did was run collaborative domain discovery sessions with product and technology leadership to understand where the real business boundaries were. What belonged to Banking. What belonged to the Matching domain. What was shared infrastructure. What was genuinely entangled and would need careful negotiation to separate. These sessions shaped the team assignments and, critically, they shaped what we decided to pull out first.
The decision I made was to extract the Banking domain into a separate repository as a smaller, cleaner Java Spring Boot application. Not a microservice. A modular monolith. Same technology stack, cleaner scope, its own database eventually, but still a single deployable unit. The reason was straightforward: with six teams and forty engineers all working on the same codebase simultaneously, attempting a direct monolith-to-microservices migration across all domains at once carried risk I was not willing to accept. The monolith released once every two weeks. With forty engineers sharing that cycle, a single problem at deployment blocked everyone simultaneously. That was not a theoretical risk. It was the regular experience. Pulling Banking out first, cleanly, gave us a controlled surface to work from.
We defined an API connecting the new Banking application to the original monolith. Full compatibility in both directions. We agreed on source of truth for each entity group. Applicant data and the original Loan Application record stayed in the monolith. Brokerage Application data and the communication records between platform and banks belonged to Banking. This agreement was more important than any technical decision we made. Without it, the data duplication we were about to introduce would have created more problems than it solved.
Nine Months of Running Both

The four moves, from extraction to decomposition. Death Valley sits between moves two and three.
Once Banking was extracted and running alongside the monolith, we enriched the data model. The C2C schema had shaped everything, including concepts that made no sense for B2C. We redesigned where it mattered, implemented a mapping layer at the domain entry point of the new platform, and published two API versions in Swagger: one fully compatible with the old monolith schema, one representing the enriched model optimised for B2C flows.
For the sync back to the monolith we used an asynchronous push service built on RabbitMQ. The monolith was running ActiveMQ. The choice to use RabbitMQ for our side was deliberate: better tooling, better observability, and it kept the complexity of the synchronisation logic contained within our domain rather than spread across both systems. Update ordering was managed with traffic light logic backed by RabbitMQ and Redis.
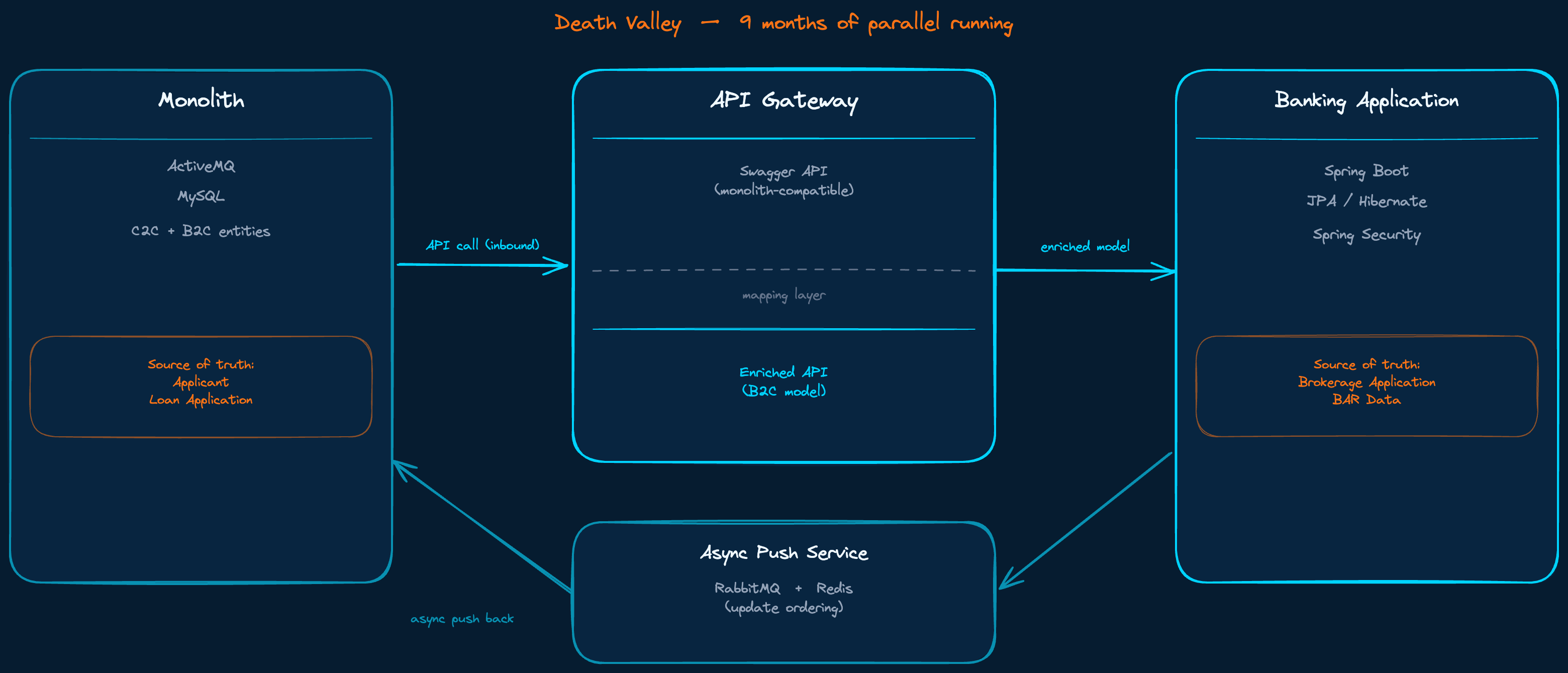
Both systems alive simultaneously. Data flowing both ways. Source of truth split deliberately across entity groups.
What I am describing here is what Nick Tune, in his book Architecture Modernization, calls Death Valley. The period during a migration where you are neither the old system nor the new one. Both are alive. Both must be maintained. The cost of running two systems in parallel is not just operational. It is cognitive. Every engineer on the team has to hold two models in their head. Every change has to be validated on both sides. Every edge case that surfaces has to be resolved against two sources of truth.
We spent nine months in that state. It was the hardest part of the entire migration, harder than any technical problem we solved. What made it survivable was the data agreement we had made at the start. When the source of truth for each entity was clear and respected by all departments, including Business Analytics and Data Science who were also migrating their data dependencies, the parallel running period had a structure. It was not clean. But it was manageable.
The Architecture Shaped the Teams
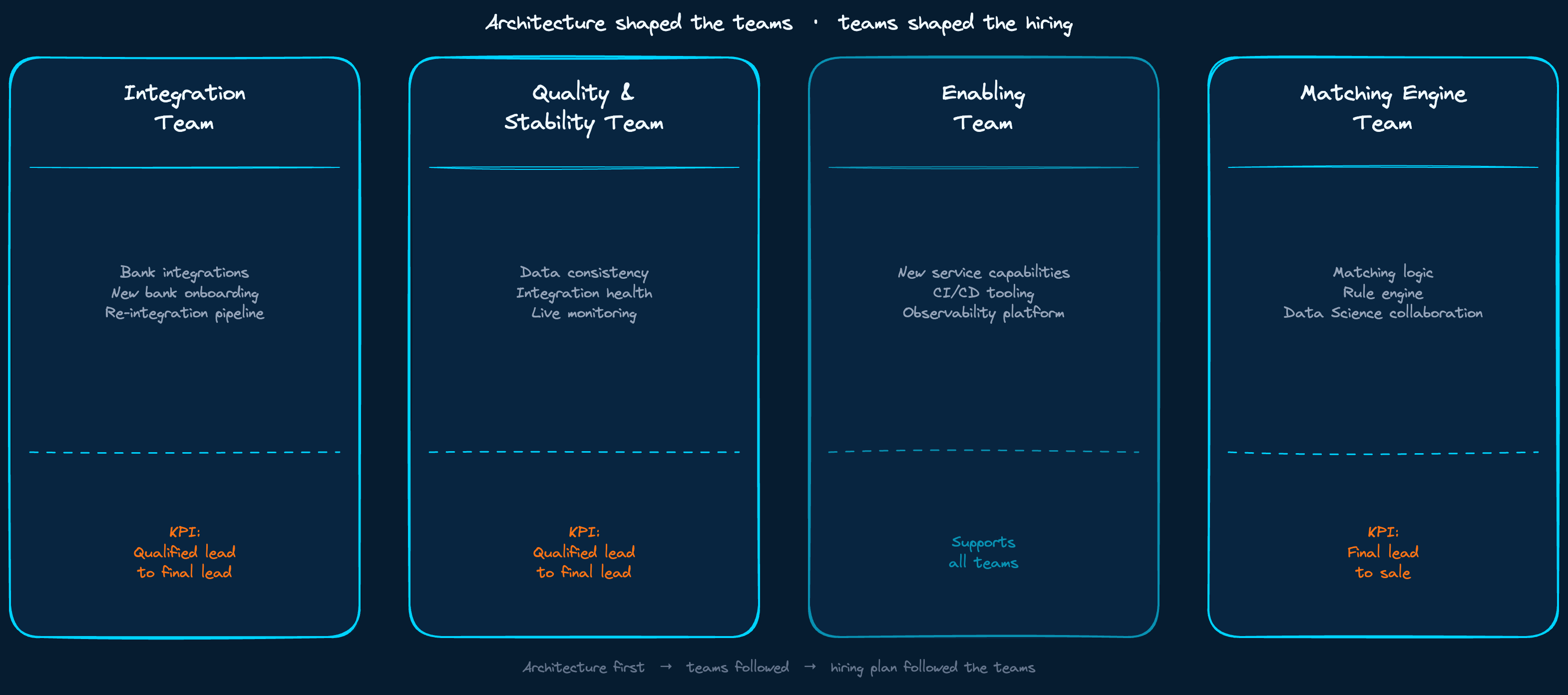
Architecture first. Teams followed. Hiring followed the teams.
Here is the thing I underestimated going in, and it changed how I thought about every migration I worked on afterward.
The forty engineers working on the original monolith were not producing a chaotic codebase by accident. The organisation structure was producing the architecture it deserved. Teams with unclear boundaries were building code with unclear boundaries. This principle, that your system architecture will tend to mirror your communication structure, is something I understood intuitively during this work, and only found formally articulated much later.
What we did differently was design the architecture first, then build the teams to match it. As we extracted Banking and began decomposing it into services, the team structure followed. One team focused entirely on onboarding new banks and re-integrating existing ones into the enriched data model. A separate team owned quality, consistency, and stability across all live integrations. A third team worked on new service capabilities without being blocked by maintenance cycles. And a fourth team worked on the matching engine connecting customer applications to the right bank products, in close cooperation with Data Science.
When I later read Team Topologies by Skelton and Pais and came across the Enabling team pattern, a team that exists specifically to unblock others and accelerate capability without owning delivery, I recognised what that third team had been. We arrived there by necessity, not by framework.
Hiring followed the same logic. The team grew from eight engineers to twenty over this period, and each hire was shaped by the architectural role that needed filling, not by a generic headcount plan.
When the Strangler Pattern Actually Arrived
The Strangler Pattern, properly applied, came in the later phases when we began decomposing the Banking application itself. By this point we had the domain knowledge, the team structure, and the observability infrastructure to do it responsibly.
New services were built to run in shadow mode alongside the existing Banking application. Traffic allocation, feature flags, Grafana and Prometheus dashboards comparing both paths, Splunk for log analysis. We did not switch over until parity was demonstrated. For bank integrations specifically, this meant multiple stakeholders, Key Account, Sales, and the banks themselves, confirming that quality was there before the old integration path was retired.
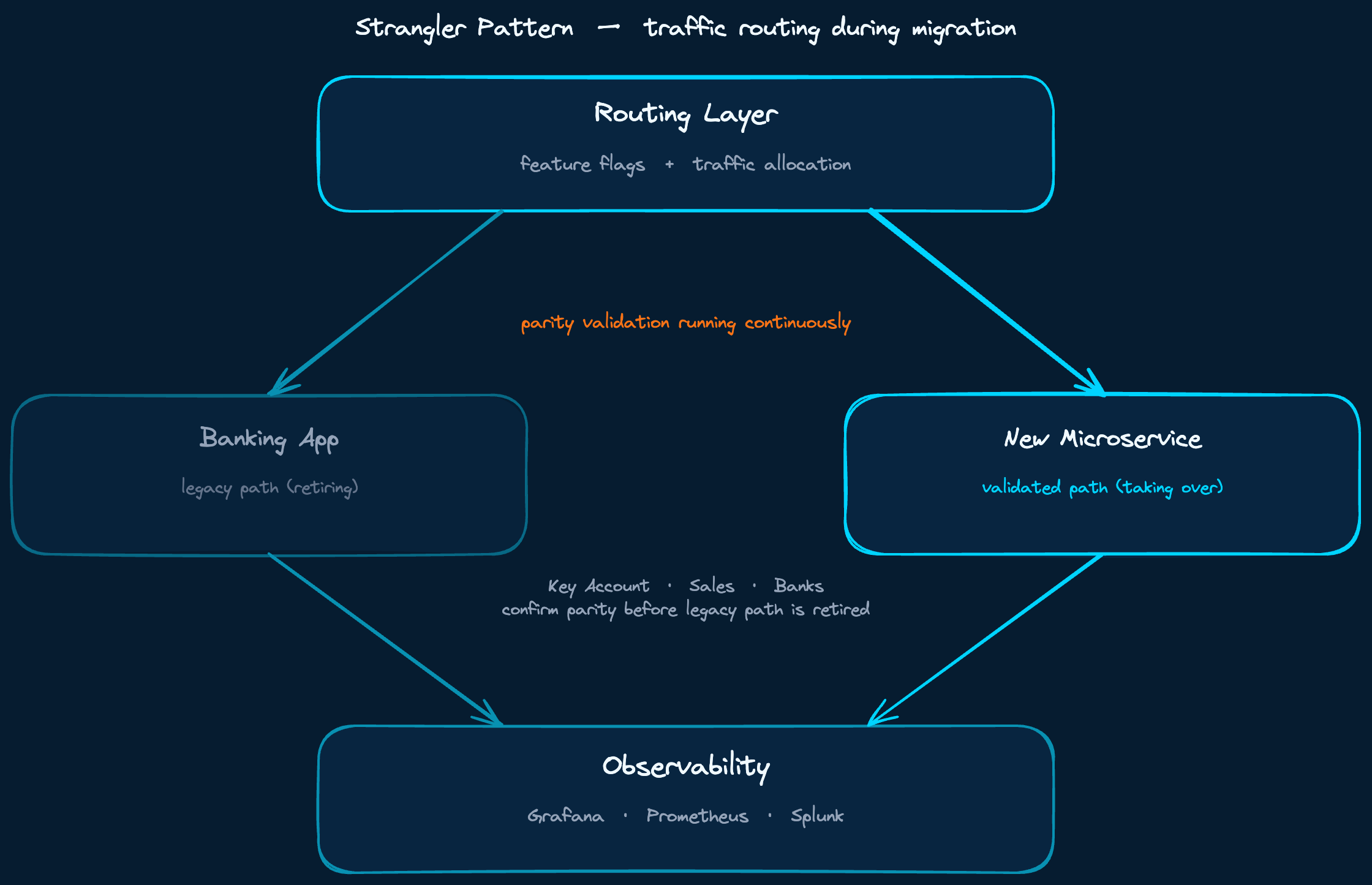
Traffic split between legacy and new paths. Nothing switched over until parity was confirmed by all stakeholders.
By the end, the Banking application we had originally extracted from the monolith was gone. Not as a goal in itself, but as a consequence of decomposing it correctly, service by service, until it was no longer needed.
What the Business Was Actually Measuring
Two KPIs shaped every decision we made. The first measured qualified leads reaching final status, the rate at which a customer’s application could actually be matched to a bank in our portfolio that could fulfil it. The second measured final lead to sale, the conversion of matched applications to completed loan agreements.
The first KPI was sensitive to the quality and coverage of our bank integrations. Every new bank onboarded, every integration rebuilt on the enriched data model, moved this number. In the monolith, onboarding a new bank took six to eight weeks. After the migration, the same work took one to two weeks. That difference is not a technical metric. It is a business metric expressed in time-to-revenue.
The second KPI was sensitive to the matching engine’s ability to find the right product at the right moment in the customer journey. The original matching logic was rule-based, a static engine that encoded business assumptions as conditions. It worked, but it could not learn and it could not adapt. Replacing it with a machine learning model had been on the table for a while. The problem was that every prerequisite for doing it responsibly, clean isolated data, independent deployment, a team with enough autonomy to iterate without coordinating with six other teams, only became available after the microservice architecture was in place. The accuracy improvement when the ML model finally replaced the rule engine was significant. But the path to getting there ran entirely through decisions that looked purely architectural at the time.
Technical modernisation served these numbers directly. It was not a separate initiative. The architecture gave us the ability to add banks faster, to rebuild integrations without touching unrelated parts of the system, and eventually to give the matching engine team enough autonomy to run experiments they could never have attempted inside the original monolith.
The technical decisions and the business decisions were the same decisions. We just made them in the right order.
That is the only measure of a migration that matters.
