
My first plan was the right one. That is what made it hard to abandon.
When I joined a fintech startup as Head of Engineering, the platform ran on a Python/Django monolith. The company was building a financial product brokerage for SMEs, connecting small businesses with the right products through a complex matching and application workflow. The platform was working. But it was not keeping up with where the business needed to go. Feature delivery was slow, measured in months where the business expected weeks. The platform’s core functionality had performance problems that were not edge cases. Security posture was largely unmeasured.
The monolith underneath all of this was deeply entangled. Entities from one business domain were referenced freely inside modules that belonged to completely different ones. Twelve engineers in three teams were sharing a codebase that did not allow any of them to move independently. Every release required coordination. Every change carried the risk of touching something unrelated. I described it to the team as a plate of colourful spaghetti. Each colour was a module. Each domain was a family of colours that belonged together. In a healthy system, the warm colours stay with the warm colours and the cool colours stay with the cool colours. What we had instead was a plate where strands of every colour had woven themselves through every other colour’s territory, so thoroughly that in the middle of the plate you could no longer tell which family a strand came from.
My instinct was to fix it properly. But I also knew that fixing a codebase this entangled without first understanding where it should end up was not fixing. It was rearranging.
Before Any Code Moved
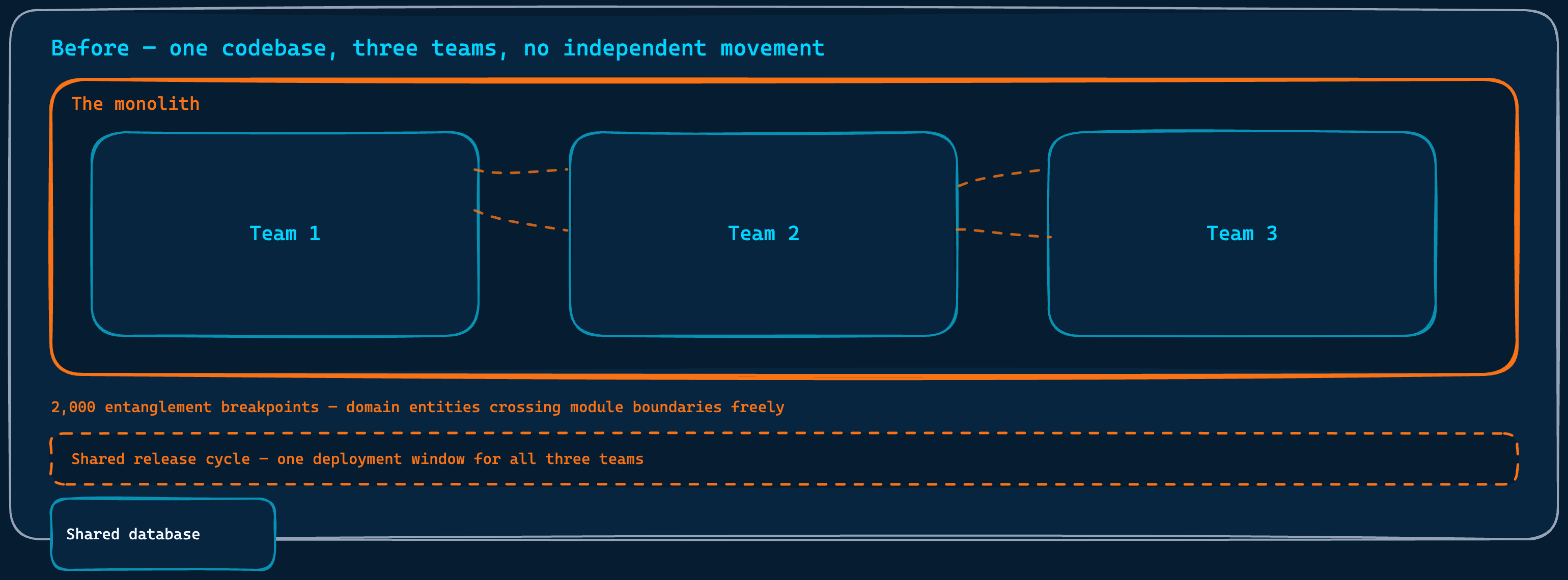
One codebase, three teams, no independent movement. Every change a shared risk.
The first year was not about the monolith. It was about building the conditions in which any meaningful change to it was possible at all.
The platform was already running in the cloud, but in a way that gave us almost none of the benefits cloud infrastructure is supposed to provide. There were no multiple environments, no proper observability stack, no meaningful monitoring. CI/CD existed in name more than in practice. I decided we needed to approach this differently. We built multiple environments with clear promotion paths, observability across every layer of the platform, and test automation as a baseline expectation rather than an optional extra. Modern CI/CD pipelines went in that teams actually owned end to end. Security and efficiency became team responsibilities with measurable targets, not something handled separately by someone else. Performance metrics moved from invisible to owned.
The team structure needed to reflect how the work was actually organized. Hiring needed to fill gaps that had been papered over. We introduced a career ladder and growth plans, not because they were administrative exercises, but because people moving in the same direction need to know what that direction looks like for them individually. We implemented DORA metrics so delivery performance became something we could see rather than argue about.
The work that mattered most for what came later was the DDD program. I introduced Domain-Driven Design as the lens through which the team would understand what it was building. We ran Event Storming sessions, first at the Big Picture level to map the entire business, then at the Process Modeling level to go deeper into the flows that mattered most. What came out of those sessions was not just shared understanding, though that alone was valuable. What came out was a domain context map, capturing the bounded contexts, their relationships, the ubiquitous language for each, and the KPIs that defined success inside each boundary.
From that, we built the North Star Architecture: a C4 target model showing five independent Go domain services, each with its own database and message broker, each owning a clearly defined part of the business. Each service covered a distinct stage of the customer journey, from how a customer first entered the platform all the way through to the outcome they came for.
That diagram became the reference point for every technical decision that followed. Without it, the modularization work I am about to describe would have had no defined target. The breakpoints we counted would have been noise.
Two Thousand Points of Entanglement
We mapped the modules against the North Star. The spaghetti metaphor became a measuring instrument: every place in the code where a module from one domain reached into the territory of a different domain was a breakpoint. A strand of one colour family running where it did not belong. We built custom linters to count them. Not as a one-time audit, but as a continuous measure, tracked over time, visible to everyone on the team.

Each colour is a module. Each domain is a family of colours. A breakpoint is a strand from one family running through another family's plate.
There were two thousand of them.
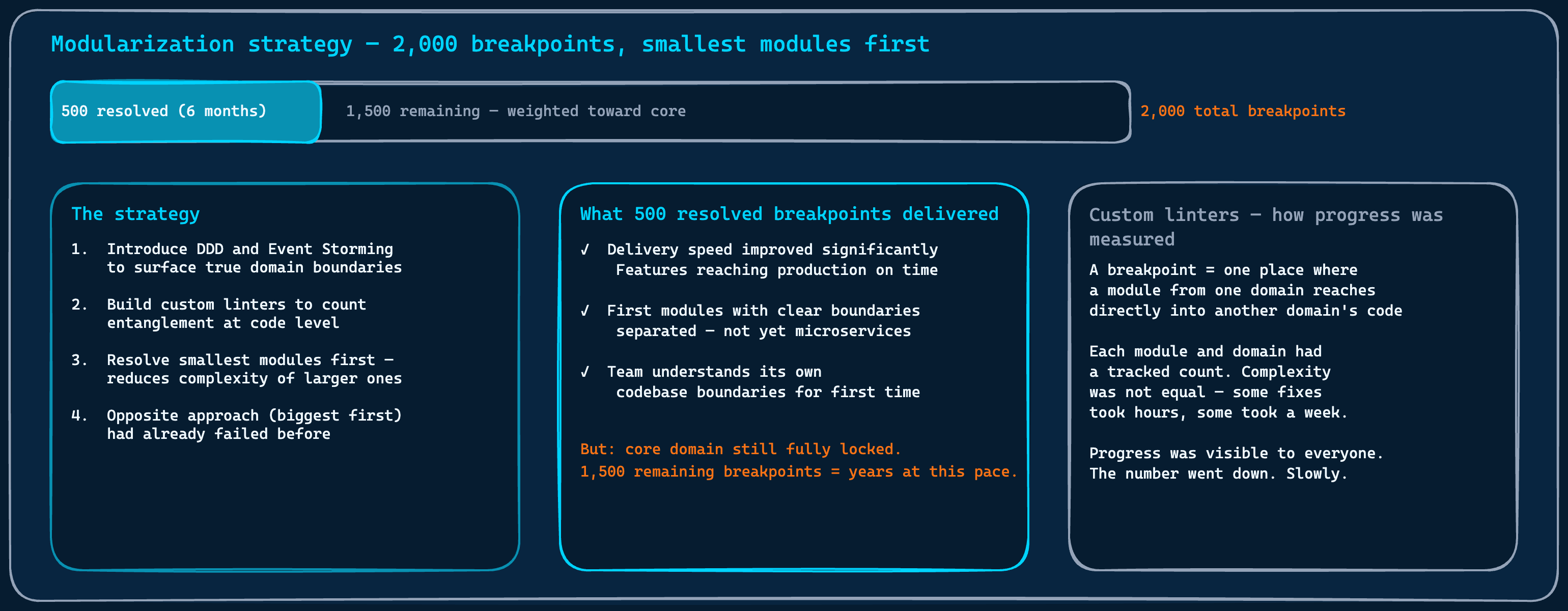
2,000 breakpoints measured against the North Star. The strategy: smallest modules first, making the biggest ones progressively easier to reach.
The strategy was deliberate. We did not start with the most important parts of the system. We started with the smallest, least entangled modules first. The logic was straightforward: removing smaller modules would reduce the complexity of the larger ones, making them progressively easier to separate. The opposite approach, attempting to extract the biggest, most central components first, had been tried before I joined. It had not worked. I had no intention of repeating that.
Six months in, we had resolved five hundred breakpoints. And the results were already visible in ways that mattered to the business. Delivery speed had improved. Features were reaching production on time for the first time in a while. Teams were stepping on each other less. The coordination overhead that had been invisible to everyone except the people doing the work was visibly shrinking. Five hundred breakpoints resolved did not look like much against two thousand. But the delivery improvement it produced was real, and the business noticed it.
We stopped there. Not because the approach was wrong, but because continuing to invest in it for the remaining fifteen hundred breakpoints was not a trade-off I could justify. The value had been extracted. The core domain was still locked, and the effort required to reach it through modularization alone was too high relative to what the business needed from us next.
That decision to stop is what made the next step possible.
What My Principal Engineer Understood
The proposal came from my Principal Engineer. He was part of the Enabling team we had structured following Team Topologies by Skelton and Pais, and what he did next was that model working exactly as intended. His approach was careful, evidence-based, never pushing, always placing ideas where they could be found and evaluated on their own merit. He was not just technically strong. He was making the people around him more capable without making them dependent on him.
The idea was Change Data Capture: specifically, Debezium. Instead of untangling the monolith’s code to extract a domain, we would mirror its database changes as an event stream. A new service would consume those events, build its own read model, and run alongside the monolith without touching it. Write ownership would stay there until the new service was stable and tested. Then ownership would transfer, and the monolith’s version of that domain would become dead code waiting to be removed.
I trusted this person. His track record had been consistent: careful thinking, honest assessment of risk, no attachment to his own ideas over better ones. When someone like that proposes a different direction, the right response is to listen, not to defend the original plan.
I was also honest with myself about what the data was showing. Five hundred of two thousand breakpoints in six months meant the remaining work, weighted toward the most complex entanglements, was going to take considerably longer. The timeline for freeing the core domain through modularization alone was not one the business could absorb.
Why Kafka Was the Wrong Answer
Before the approach could work, there was a decision that mattered more than it appeared: where would Debezium route the database change events?
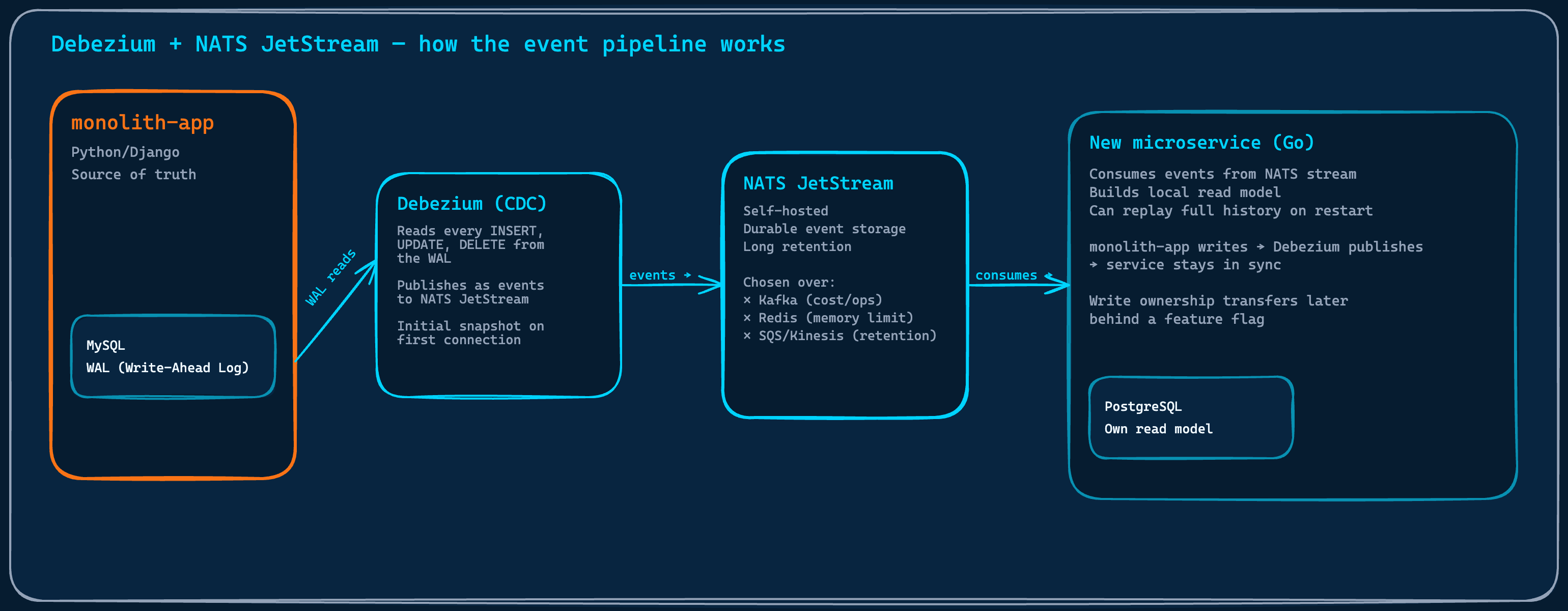
Debezium reads every database change at the WAL level. NATS JetStream holds the event stream. New services build their own read models and replay from the beginning when needed.
Kafka was the obvious first option and the standard recommendation for Debezium deployments. Managed Kafka on AWS was prohibitively expensive for our requirements. Self-hosting Kafka on our cluster introduced operational complexity that was not proportionate to the team size and the problem we were solving. We ruled it out.
Redis streams were considered next, given our existing infrastructure. The constraint appeared quickly: Redis is in-memory storage. A trial run connecting Debezium to a single table in the monolith hit the memory limit within the trial period. Even the largest Redis instance available would not have been sufficient for the full volume of events we needed to retain, and the cost trajectory was not favorable. We dismissed it.
SQS and Kinesis were evaluated and ruled out for a different reason. The retention periods did not match the approach’s requirements. The entire point of this pattern is that a new service can replay the full event history to rebuild its read model from scratch. Short retention made that impossible.
What remained was a self-hosted solution lightweight enough to manage with a small platform team and durable enough for long-term event retention. After evaluation, we chose NATS JetStream. It handled the requirements cleanly and added no operational burden we were not already equipped to carry.
What the Extraction Actually Looked Like
The first extraction was chosen deliberately: a contained domain, a clear owner, a team willing to run the experiment.
Real problems surfaced immediately. A Debezium instance going down mid-stream left a message in a state where it had been read but could not be acknowledged, blocking the consumer from processing anything further. The fix required a manual acknowledgment through the NATS CLI and a code change to handle conflict scenarios without failing hard. Eventual consistency created a visible edge case in the frontend: a document uploaded through the monolith would not appear immediately in the new service’s read model, because the Debezium event had not yet propagated. The frontend had to be updated to hold the newly uploaded document in local state rather than refetching from the service.
The Debezium deployment strategy itself needed adjustment. Running two connector versions simultaneously during an upgrade produced duplicate messages in the stream. The metadata differed but the content was identical. We solved it by switching to a recreate deployment strategy, where the old instance is fully stopped before the new one starts.
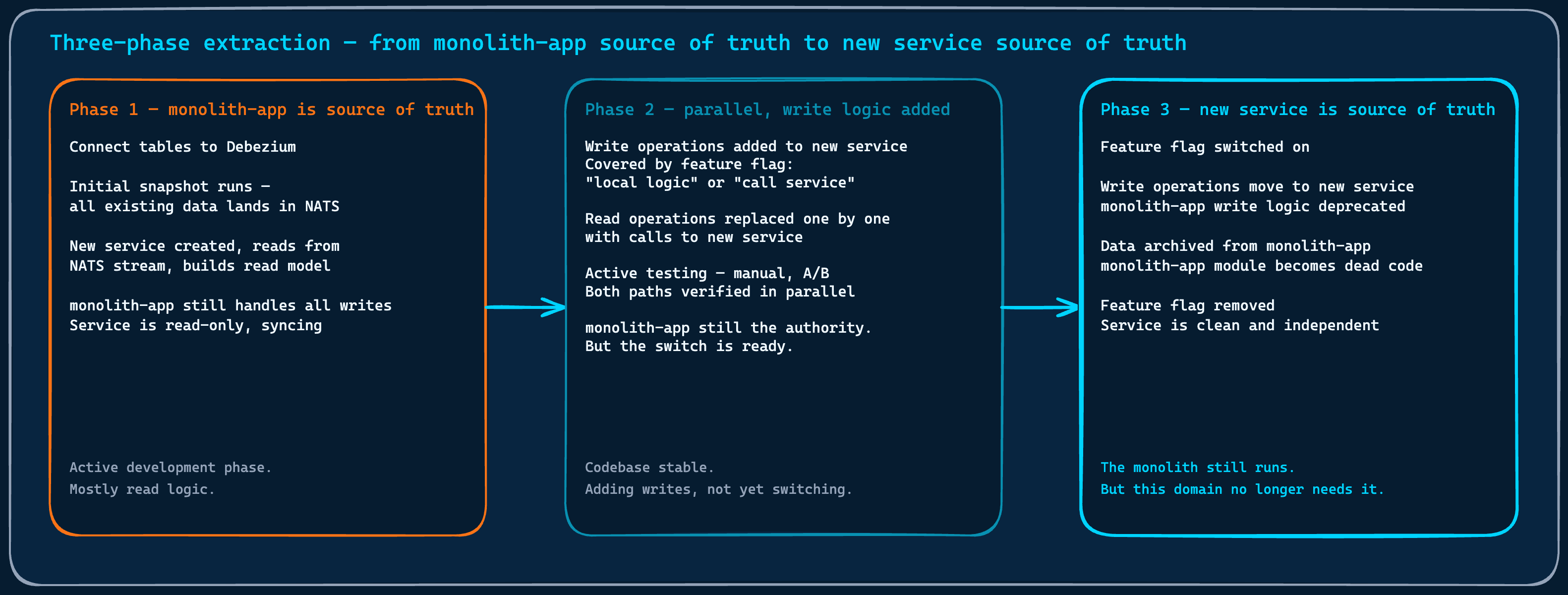
The monolith stays the source of truth until the new service is proven. Write ownership transfers behind a feature flag. Then the monolith's version becomes dead code.
None of these were blockers. They were the normal friction of applying a tool in a new context. Each problem found a clean resolution, and each solution became part of the shared knowledge the team carried into the next extraction.
By the time the core domain work was complete, around five services had been extracted. The platform’s most critical functionality ran entirely outside the monolith’s release cycle. Deployments in the core domain moved to on-demand, multiple times a day when the work required it. The performance problems that had been hitting users were resolved. The product overview at the heart of what the company offers to its customers ran on infrastructure that no longer shared a fate with the monolith.
The Thing Worth Saying About Technical Debt
The modularization work was not wasted. The five hundred breakpoints we resolved delivered real value: faster delivery, cleaner module boundaries, a team that understood its own codebase better than before. For domains that could not justify full extraction as independent services, modularization remained the right answer.
But for the core, the answer was different.
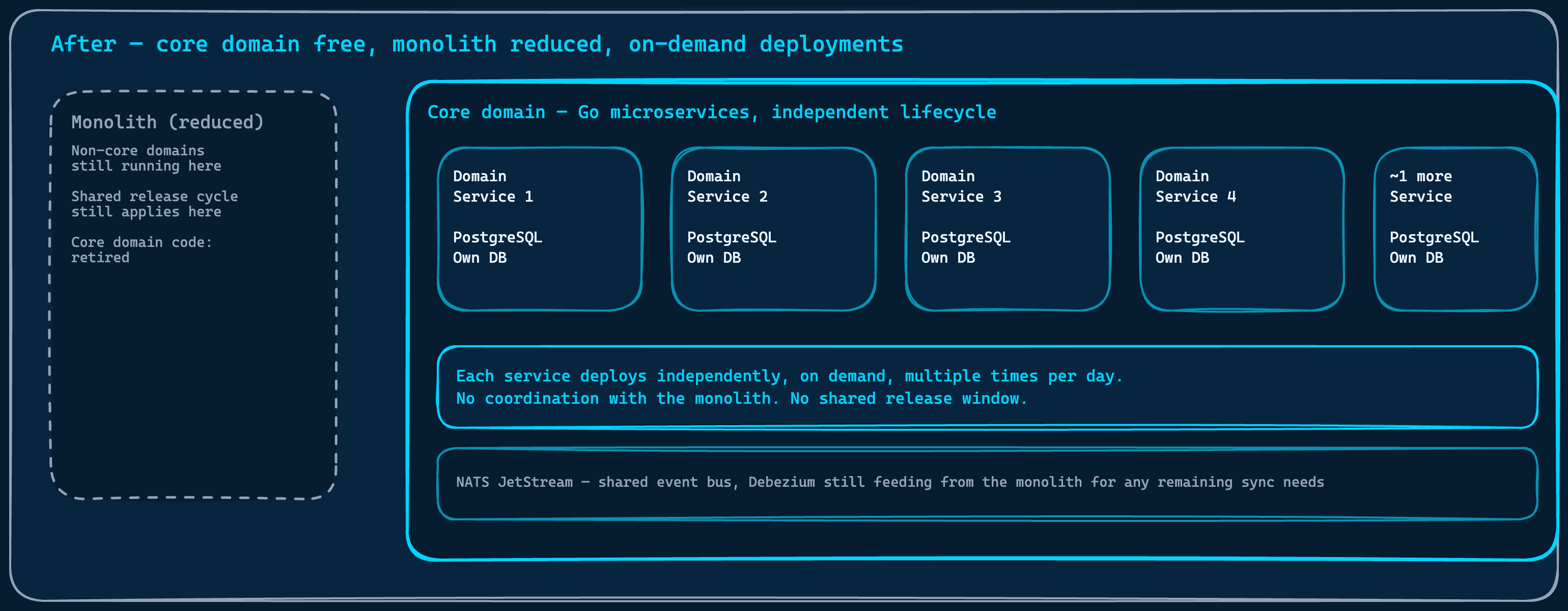
The core domain freed entirely from the monolith's lifecycle. Five services. Independent deployments. The monolith still running, but no longer the thing that mattered.
The temptation I had to resist when I backed the CDC approach was not impatience with the original plan. It was the sunk cost of the work already done and the direction already committed to. Changing course mid-way felt like saying the first plan was wrong. It was not wrong. It was right for a different problem. The core domain needed something modularization could not give it in the time the business had.
There is a version of technical leadership that defines itself by cleaning up what is messy. I understand that instinct. But cleaning requires touching, and touching the most entangled parts of a legacy system is expensive in ways that are not always linear. Sometimes the code that needs the most attention is also the code most likely to resist it.
We did not fix the monolith. We made it irrelevant.
That is sometimes the only honest answer to technical debt. Not all of it needs to be repaid. Some of it just needs to be left behind, cleanly, once something better has been built to take its place.
